¶ RKNN usage
The RKNN software stack can help users quickly deploy AI models onto Rockchip chips. In order to use RKNPU, users need to first run the RKNN-Toolkit2 tool on their computer to convert the trained model into an RKNN format model, and then deploy it on the development board using the RKNN C API or Python API.
The RKNN software stack can help users quickly deploy AI models onto Rockchip chips. The overall framework is as follows:
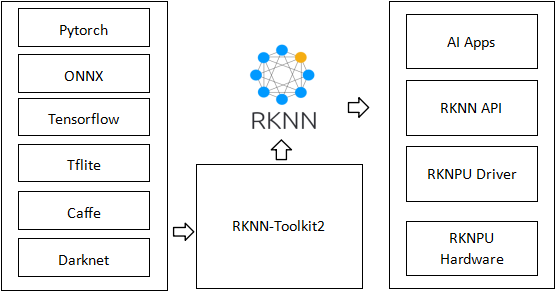
In order to use RKNPU, users need to first run the RKNN-Toolkit2 tool on their computer, convert the trained model into an RKNN format model, and then use the RKNN C API or Python API for inference on the development board.
- RKNN-Toolkit2 is a software development kit designed for users to perform model transformation, inference, and performance evaluation on both PC and Rockchip NPU platforms.
- RKNN-Toolkit-Lite2 provides a Python programming interface for Rockchip NPU platform, helping users deploy RKNN models and accelerate the implementation of AI applications.
- The RKNN Runtime provides a C/C++programming interface for the Rockchip NPU platform, helping users deploy RKNN models and accelerate the implementation of AI applications.
- The RKNPU kernel driver is responsible for interacting with NPU hardware. It has always been open source and can be found in the Rockchip kernel code.
¶ 1 RKNN Toolkit2 Function Introduction
RKNN-Toolkit2 is a development kit that provides users with the ability to perform model transformation, inference, and performance evaluation on a computer,
The main block diagram of RKNN-Toolkit2 is as follows:
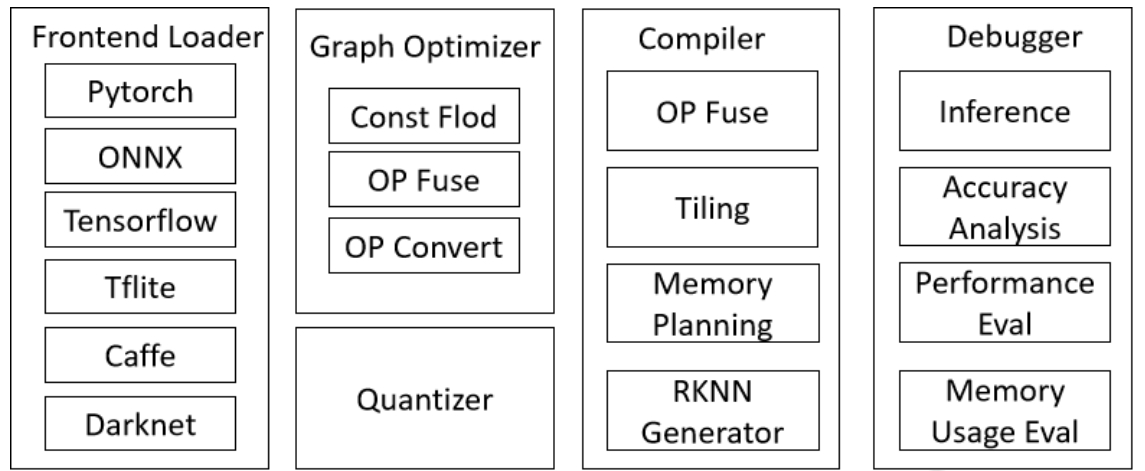
The Python interface provided by this tool allows for easy completion of the following functions:
- Model Conversion: Supports converting PyTorch, ONNX, TensorFlow, TensorFlow Lite, Caffe, DarkNet, and other models to RKNN models.
- Quantization Function: Supports the quantization of floating-point models into fixed-point models and supports mixed quantization.
- Model inference: Distribute RKNN models to designated NPU devices for inference and obtain inference results; Or simulate NPU on a computer to run RKNN model and obtain inference results.
- Performance and Memory Evaluation: Distribute the RKNN model to specified NPU devices to evaluate the performance and memory usage of the model when running on actual devices.
- 'Quantitative accuracy analysis': This function will provide the cosine distance and Euclidean distance between the inference results of each layer of the model after quantization and the inference results of the floating-point model, in order to analyze how quantization errors occur and provide ideas for improving the accuracy of the quantization model.
- Model Encryption Function: Encrypt the entire RKNN model using a specified encryption level.
¶ 2 Introduction to RKNN Runtime Function
The RKNN Runtime is responsible for loading the RKNN model and calling the NPU driver to infer the RKNN model on the NPU. When inferring RKNN models, there are three processes involved: raw data input preprocessing, NPU running the model, and output post-processing.
// TO DO